P5 Archive:メタデータ等を外部ソースからアーカイブインデックスにインポート
この記事では、既存のアーカイブインデックスにメタデータ、サムネイル、プロキシをインポートするワークフローについて説明します。
P5 Archiveで既にアーカイブされ、アーカイブインデックスに表示されているデータは、外部ソースからデータとJPEG/MP4ファイルを提供することで、これらの追加項目を追加することができます。
この機能を使用するには、P5のバージョン7.1.6以降が必要です。
P5 Archive: Importing metadata, thumbnails and proxies into archive indexes from external sources
この作業例では、P5をセットアップし、すでにいくつかのアセットをアーカイブしているが、これらのアセットにはアーカイブ インデックスにメタデータ、サムネイル、プロキシが添付されていない場合を想定しています。
場合によっては、別のソフトウェア製品で書き込まれたLTFSフォーマットのLTOテープがP5にインポートされていることもあります。
これらのアセットでは、追加のメタデータが利用できる場合があり、このデータをCSV形式にエクスポートして、後述の方法でP5がインポートできるようにすることができます。
多くの場合、MAMシステムはすでにそのような情報を保持しており、これをCSV形式でエクスポートしてマージすることができます。
この情報をP5のアーカイブインデックスにインポートする基本は、アーカイブインデックス内の各アセットをフルパスとファイル名で参照するCSVファイル(カンマ区切りの値)を作成し、その後にメタデータ値とサムネイルJPEGファイルとプロキシMP4ファイルのフルパスとファイル名を追加することです。
インデックスのエクスポート
このCSVファイルのベースとなるテキストファイルを作成するには、アーカイブインデックスの内容全体をダンプアウトするP5のCLIコマンドを使用するのが便利です。
LinuxおよびmacOSシステムでは、ターミナル/シェルで、以下のコマンドを実行すると、作業ディレクトリがP5のインストールディレクトリに変更され、nsdchatユーティリティを使用してP5と対話し、名前付きインデックス「Default-Archive」を「inventory.txt」という名前の同じディレクターのファイルにダンプアウトします。
cd /usr/local/aw
bin/nsdchat -c ArchiveIndex Default-Archive inventory inventory.txt
Windowsシステムでは、コマンドプロンプト・ウィンドウで、以下の2つのコマンドを使用してディレクトリを変更し、CLIコマンドを実行します。
cd "\Program Files\ARCHIWARE\Data_Lifecycle_Management_Suite"
.\bin\nsdchat.exe -s awsock:/admin:admin@127.0.0.1:9001 -c ArchiveIndex Default-Archive inventory inventory.txt
どちらの場合も、カレントディレクトリに「inventory.txt」という名前のファイルが作成され、アーカイブインデックスのファイルまたはディレクトリごとに1行が含まれます。この例では、ファイルの先頭は次のようになります:
/
/data
/data/metadata-ingest-test
/data/metadata-ingest-test/010bike.jpg
/data/metadata-ingest-test/011bike.jpg
/data/metadata-ingest-test/013bike.jpg
/data/metadata-ingest-test/022runner.jpg
/data/metadata-ingest-test/023runner.jpg
/data/metadata-ingest-test/025runner.jpg
/data/metadata-ingest-test/026runner.jpg
/data/Video
/data/Video/ForBiggerFun.mp4
CSV ファイルの準備
インベントリファイルには、各ファイルのエントリに加えて、インデックスの各フォルダのエントリも含まれることに注意してください。
ファイルではなくフォルダのみに関連するエントリを削除します。P5 がメタデータを添付できるのはファイルだけで、フォルダには添付できません。
このテキストファイルが、メタデータのインポートに使用するCSVファイルのベースになります。
インポートCSVをテストする簡単な方法は、このテキストファイルをスプレッドシートにインポートして、各行に他の値を追加できるようにし、そのスプレッドシートをCSVファイルとしてエクスポートすることです。
この例とGoogle Sheetsのウェブベースのスプレッドシートを使って、どのように見えるか見てみましょう。この目的であれば、どんなスプレッドシート・ツールでも問題ありません。
以下の例では、各列を説明する行を追加し、メタデータとプレビューを保持するために3つの列を追加しました。
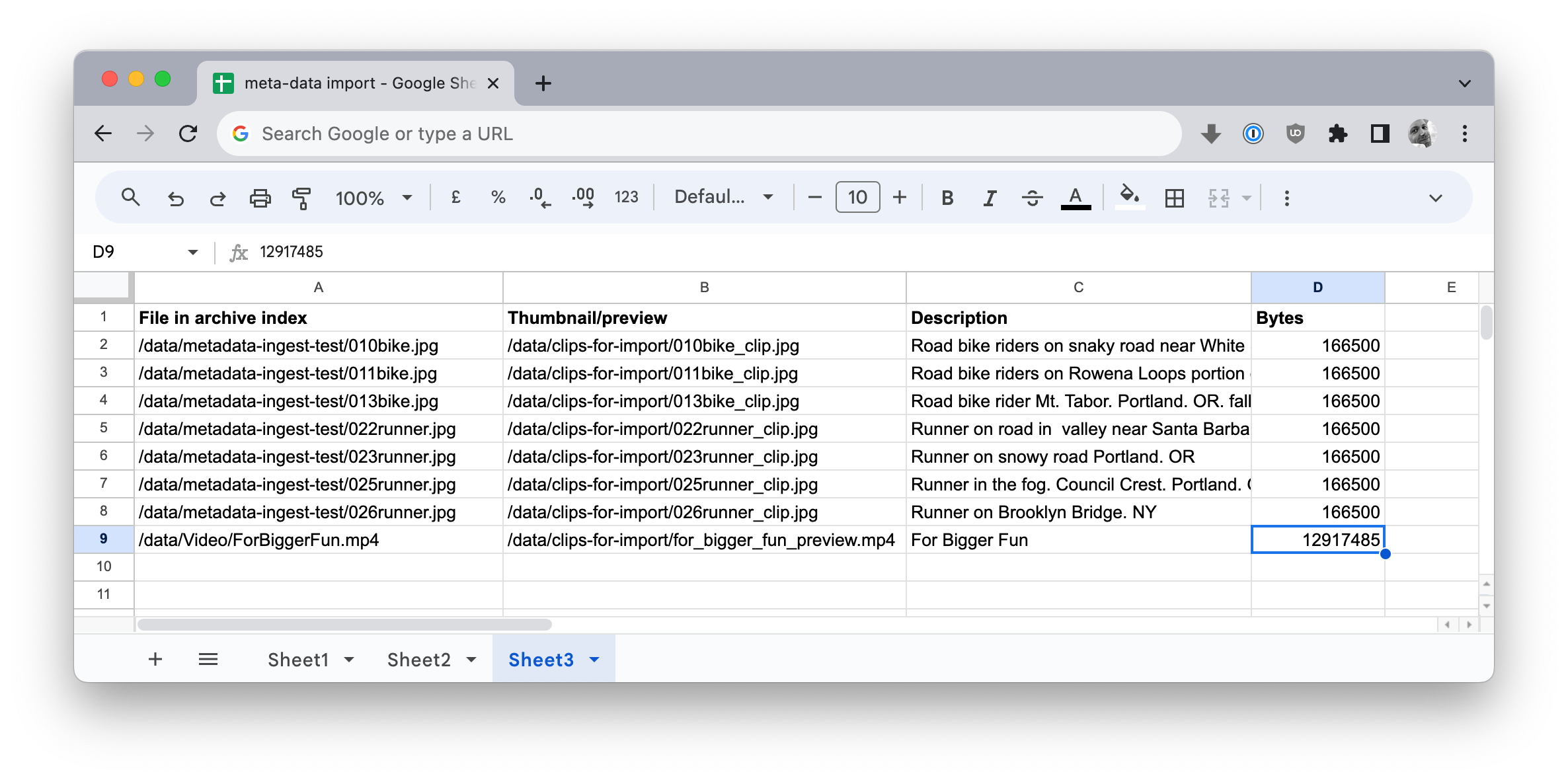
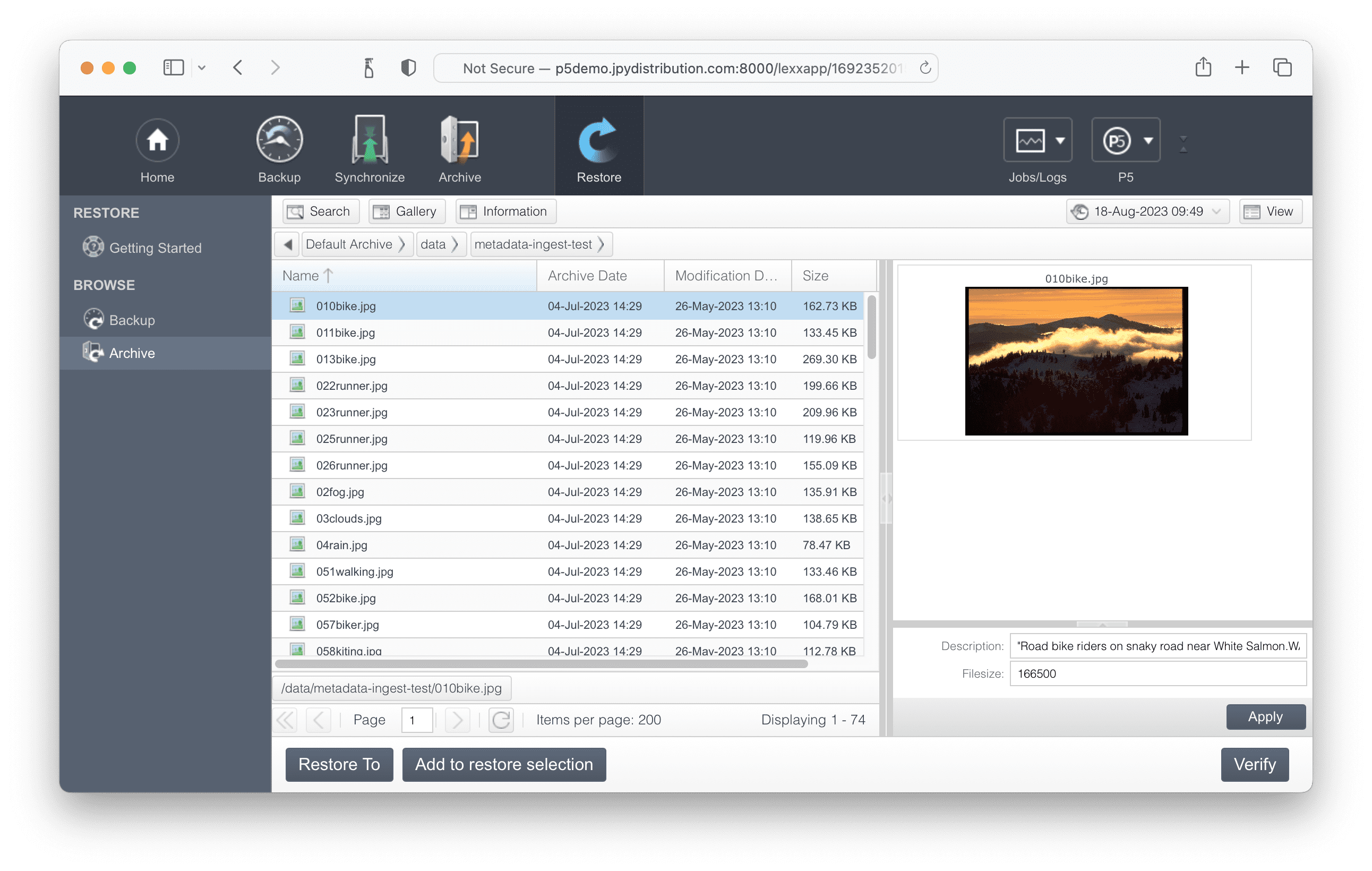
これらのサムネイルファイルは、これから実行するインポートスクリプトがこれらのファイルを見つけ、アーカイブインデックスにリンクし、P5がサムネイルを保存するフォルダに移動できるように、指定された場所に存在する必要があります。サムネイルファイルは元のアセットと同じファイル名である必要はありませんが、この例ではそうなっています。この例のC列とD列には、各メディアファイルのテキスト説明とファイルサイズ(バイト単位)が記載されています。
スプレッドシート ツールを使用して、このデータを CSV 形式でエクスポートします。必要に応じて、列の見出しを含むファイルの最初の行を削除します。
できあがったCSVファイルは、以下の例のようになります。スプレッドシートの1行につき1行、値はカンマで区切られます。このページのレイアウトでは、行が分割されていることに注意してください。
/data/metadata-ingest-test/010bike.jpg,/data/clips-for-import/010bike_clip.jpg,Road bike riders on snaky road near White Salmon.WA,166500
/data/metadata-ingest-test/011bike.jpg,/data/clips-for-import/011bike_clip.jpg,Road bike riders on Rowena Loops portion of Columbia River Scenic Highway,166500
/data/metadata-ingest-test/013bike.jpg,/data/clips-for-import/013bike_clip.jpg,Road bike rider Mt. Tabor. Portland. OR. fall leaves,166500
/data/metadata-ingest-test/022runner.jpg,/data/clips-for-import/022runner_clip.jpg,Runner on road in valley near Santa Barbara. CA,166500
/data/metadata-ingest-test/023runner.jpg,/data/clips-for-import/023runner_clip.jpg,Runner on snowy road Portland. OR,166500
/data/metadata-ingest-test/025runner.jpg,/data/clips-for-import/025runner_clip.jpg,Runner in the fog. Council Crest. Portland. OR,166500
/data/metadata-ingest-test/026runner.jpg,/data/clips-for-import/026runner_clip.jpg,Runner on Brooklyn Bridge. NY,166500
/data/Video/ForBiggerFun.mp4,/data/clips-for-import/for_bigger_fun_preview.mp4,For Bigger Fun,12917485
P5アーカイブインデックスにフィールドを追加する
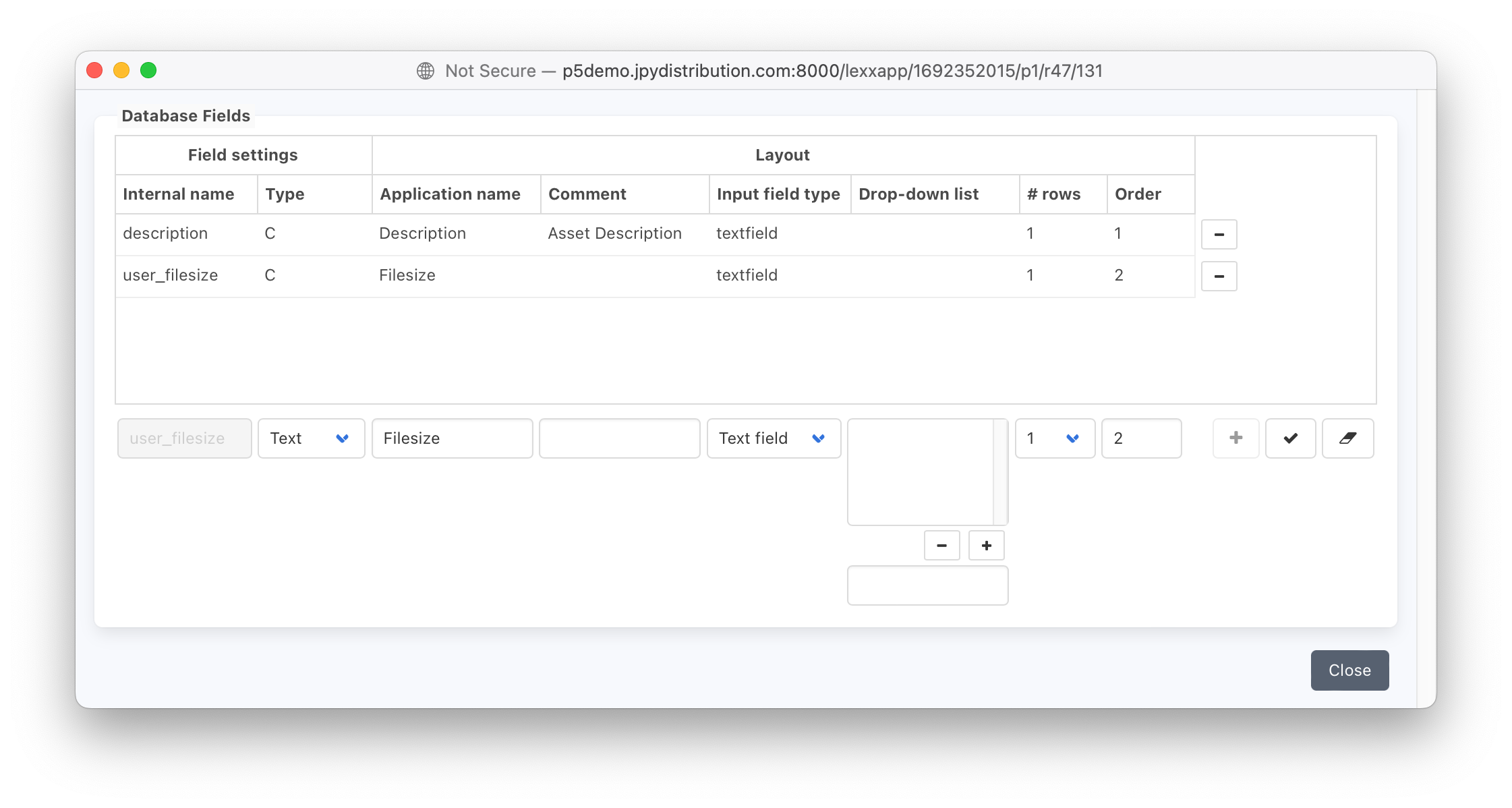
インポート用のデータが準備できたので、アーカイブインデックスに追加フィールドを作成して、ファイルのサイズをバイト単位で格納する「bytes」カラムを格納する必要があります。これを行うには、フィールドエディターウィンドウを使用します。これは、P5 Archiveタブ -> Advanced Options -> Manage Indexesからアクセスできます。フィールドを追加するアーカイブインデックスをハイライトし、右クリックして「Fields...」を選択すると、以下のウィンドウが表示されます。ウィンドウの下部に新しいフィールドを入力し、チェックボタンで上部のリストに追加します。既存のフィールドは、上の表でハイライトし、下の表で編集することができます。アーカイブ・インデックス・フィールドの追加と編集の詳細については、P5のドキュメントを参照してください。
以下の例では、新しいフィールド「user_filesize」が追加されています。'description'というフィールドはデフォルトでアーカイブインデックスに既に存在しています。
スクリプトのダウンロードと編集
シェルスクリプト(Linux/macOS)またはバッチファイル(Windows)を使って、アーカイブインデックスにデータをインポートする準備ができました。
スクリプトのシェルスクリプト版とバッチファイル版の両方を含むZIPファイルをこちらからダウンロードしてください。
これらのスクリプトは、特定のワークフローに適したフィールドをインポートするように、少し編集/微調整が必要です。ダウンロードしたスクリプトは、上記のリンク先のビデオに示されているように動作し、上記のCSVファイルに示されているフィールドを見つけることを想定しています。これらのスクリプトを変更するには、シェルスクリプトとバッチファイルについてある程度理解している必要があります。インポートにフィールドを追加する方法について、ごく簡単に説明します:
Linux/macOSのシェルスクリプトには、CSVファイルの各行を繰り返し処理するループがあります:
while read fpath cpath descr fsize
fpath、cpath、descr、fsizeは、CSVの各行から読み込まれる値に関連する。スクリプト内でのみ有効な独自の名前を使用して、必要に応じて値を追加してください。
/usr/local/aw/bin/nsdchat -s awsock:/$user:$pass:311@$ipAddress:9001 -c ArchiveEntry $aEntry setmeta user_filesize {$fsize} > /dev/null 2>&1
上の行はP5のCLIインターフェイスを呼び出し、アーカイブインデックスのフィールド名(user_filesize)を指定し、フィールドに値fsizeを配置します。上記のような行を追加して、CSVファイルからアーカイブインデックスに追加の値を書き込みます。
Windowsのバッチファイル版のスクリプトでは事情が異なります。ここでは、CSVファイルを繰り返し処理するループは次のようになります:
FOR /F "tokens=1-4 delims=," %%A in (%csvFile%) do (
ここで重要なのは'tokens=1-4'で、これはCSVファイルに4つの値を指定するものです。この'4'の部分を、CSVで指定する値の数になるように編集してください。次に
SET cpath=%%B SET descr=%%C SET fsize=%%D
%%B、%%C、%%Dは、CSVから読み込まれる2番目、3番目、4番目の値を表します。Eを追加して5番目の値を表し、その値を格納する変数名を選択します。例:'SET caption=%%E'。最後に
!command! ArchiveEntry %%i setmeta user_filesize {!fsize!}
ここでは'fsize'の値を取り、アーカイブインデックスの'user_filesize'というフィールドに格納しています。ここに追加の行を追加して、独自のメタデータ値を保存します。
スクリプトの実行
CSVファイルを入力としてスクリプトを実行する準備ができました。これらの例では、P5のインストールディレクトリにスクリプトを配置し、Linux/macOSで実行できるようにしたものとします。スクリプトの作成方法と実行方法がわからない場合は、ライブのP5サーバーで実行する前に、Googleを使用して調査してください。
Linux/macOS上で以下のようにスクリプトを実行します。スクリプトは、P5サーバーの管理者アカウントのユーザー/パスを引数/パラメーターとして受け取り、最後にメタデータ情報を含むCSVファイルへのフルパスを受け取ります:
./metadata_import.sh admin admin 127.0.0.1 ./clips_linux.csv
Windowsシステムでは、batファイルの実行は次のようになります(P5のインストールディレクトリから実行し、CSVへのフルパスを指定します):
.\metadata-import.bat admin admin 127.0.0.1 C: \Users\Administrator\Desktop\metadata_win.csv
どちらの場合も、各ファイルがインデックスに配置され、メタデータが追加されていることを示すスクリプトからの出力が表示されません。うまくいかない場合は、スクリプトにデバッグ文を追加することで、何がうまくいっていないのかを知ることができるかもしれません。
インポートが成功すると、アーカイブのインデックスにアクセスし、サムネイルやプレビュー、インポートされたメタデータが表示され、検索できるようになります。ほとんどの場合、サムネイルやプロキシがインデックスに表示されるまで数分待つ必要があります。しかし、メタデータはすぐにインデックスに表示されるはずです。